ES란?
Elastic Search 란 ?
ES
ElastciSearch 는 Lucene 기반의 Java 오픈 소스 분산 검색 엔진
→ 자체적으로 검색 엔진이라고 하긴 좀 그렇고 프로그램으로 검색엔진 !
→ 실질적으로 작동하는 검색 엔진은 Lucene
모든 데이터를 색인하여 저장하고 검색, 집계 등을 수행하며 결과를 클라이언트 또는 다른 프로그램으로 전달하여 동작하도록 함
검색을 위해 단독으로 사용하기도 하지만 ELK 스택으로 사용되기도 함
ELK
- LogStash : 다양한 소스( DB, csv파일 등 )의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달 → 수집
- Elasticsearch : Logstash로부터 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 획득 → 분석 , 저장
- Kibana : Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링 → 시각화

ElasitcSearch vs RDBMS
| RDBMS | ES |
|---|---|
| schema | mapping |
| Database | index |
| table | type |
| row | document |
| Column | Field |
ElasticSearch 아키텍쳐 / 용어 정리
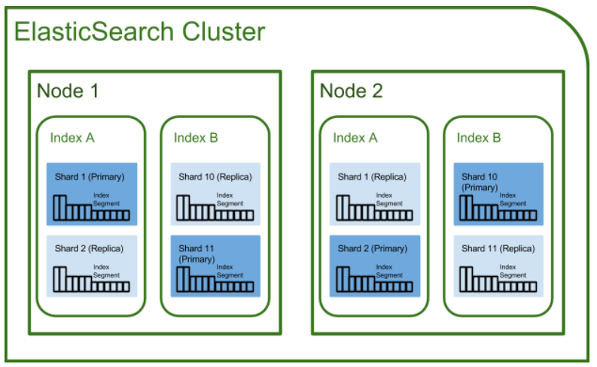
1) 클러스터( cluseter )
클러스터란 Elasticsearch에서 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드들의 집합
서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지
여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재 할 수 있음
2) 노드( node )
Elasticsearch를 구성하는 하나의 단위 프로세스를 의미
shard 로 구성됨
그 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분
**3) 인덱스( index ) **
Elasticsearch에서 index는 RDBMS에서 database와 대응하는 개념
4) 샤드( Shard ) / 복제( Replica )
샤딩( sharding )은 데이터를 분산해서 저장하는 방법을 의미합니다.
즉, Elasticsearch에서 스케일 아웃을 위해 index를 여러 shard로 쪼갠 것입니다.
기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 함
replica는 또 다른 형태의 shard라고 할 수 있음
노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제하는 것 따라서 replica는 서로 다른 노드에 존재할 것을 권장합니다.
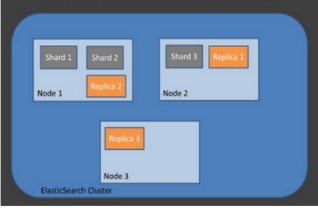
=> Cluster 은 node 들의 집합, node 들은 shard 로 구성, 데이터는 shard로 분산되어 저장
Elasticsearch 특징
-
Scale out
-
- 샤드를 통해 규모가 수평적으로 늘어날 수 있음
-
고가용성
-
- Replica를 통해 데이터의 안정성을 보장
-
Schema Free
-
- Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
- Restful
역색인(inverted index)
책에서 맨 앞에 볼 수 있는 목차가 index
책 맨뒤에 키워드마다 찾아보기가 inverted index
RDBMS
| ID | Text |
|---|---|
| 1 | I have a pen |
| 2 | I am pen |
ES
| Term | ID |
|---|---|
| I | 1,2 |
| have | 1 |
| am | 2 |
| a | 1 |
| pen | 1,2 |
Query DSL
Query Context vs Filter Context
- Query
-
이 문서가 이 쿼리절과 얼마나 잘 일치합니까 ? 라는 질문에 대답
-
얼마나 잘 일치하는 지를 _score 로 표현
- Filter
-
이 문서가 이 쿼리절과 일치합니까? 라는 질문에 대답
-
score 을 계산하지 않고 간단하게 true/false 로 리턴
-
자동으로 캐싱되어 성능을 높임
풀 텍스트 쿼리
- match_all
-
별다른 조건 없이 해당 인덱스의 모든 도큐먼트를 검색하는 쿼리
GET index명/_search
{
"query":{
"match_all":{ }
}
}
- match
-
풀 텍스트 검색에 사용되는 가장 일반적인 쿼리
-
여러 개의 검색어를 집어넣게 되면 디폴트로 OR 조건으로 검색
-
검색어가 여럿일 때 검색 조건을 OR 가 아닌 AND 로 바꾸려면
operator옵션을 사용
GET index명/_search
{
"query": {
"match": {
"message": {
"query": "quick dog",
"operator": "and"
}
}
}
}
- match_phrase
-
공백을 포함해 정확히 일치하는 내용을 검색
GET index명/_search
{
"query": {
"match_phrase": {
"message": "lazy dog"
}
}
}
- term
-
색인이 나눠지면서 형태소로 나눠지는 토큰등을 term 이라고 함
-
주어진 내용과 정확히 일치하는 내용을 검색
GET index명/_search
{
"query": {
"term": {
"message": "lazy dog"
}
}
}
- terms
-
여러개 토큰을 검색할 수 있음
GET index명/_search
{
"query": {
"term": {
"message": ["lazy", "dog"]
}
}
}
match vs term
여러 개의 물건들 - (형태소 분석기) -> 여러 / 개 / 물건 / 물건들
term : 형태소 분석에 의해 쪼개진 토큰을 기반으로 작동
EX ) 여러 -> 검색 O , 여러개 -> 검색 X
match : 형태소 분석에 의해 쪼개진 토큰들을 기반으로 작동하지만 주어진 질의로 형태소 분기를 거쳐 쪼갠 다음 조회
EX ) 여러개 -> 여러 / 개 -> or 로 조회 -> 검색 O
Bool 복합 쿼리
: bool(true/false) 로직을 사용하는 쿼리
GET index명/_search
{
"query": {
"bool": {
"must": [
{ <쿼리> }, …
],
"must_not": [
{ <쿼리> }, …
],
"should": [
{ <쿼리> }, …
],
"filter": [
{ <쿼리> }, …
]
}
}
}
- must
-
쿼리가 참인 도큐먼트들을 검색
- must_not
-
쿼리가 거짓인 도큐먼트들을 검색
- should
-
검색 결과 중 이 쿼리에 해당하는 도큐먼트의 점수를 높임
- filter
-
쿼리가 참인 도큐먼트를 검색하지만 스코어를 계산하지 않음
-
must 보다 검색 속도가 빠르고 캐싱이 가능